
Welcome! In this gifting stats post we use a data-driven approach to answer a basic but important question that will help people with their gifting problems: Who do people struggle finding gifts for?
Table of Contents
Goal
Our goal is very simple: to help people with amazing gift ideas. Knowing your audience inside and out is key to determining their struggles and discovering how you can help. Gifting is no different, and in this post we will be using a data-driven approach that takes advantage of recent advances in machine learning and natural language processing (NLP) to better understand our audience and what gift recipients they need help with. Specifically, we will be learning who people struggle to buy gifts for the most.
Data
The plan for any statistical analysis always starts with data. But where does one find data on gifting? One option is conducting a survey asking people questions about buying and receiving gifts, but that takes time and is difficult to get a lot of responses. Fortunately, there is a vast data lake of relevant information already on the internet, if you know where to look and how to extract it.
In this post, we will use posts made on the subreddit r/giftideas as our dataset. r/giftideas is a subreddit where thousands of people ask for gift ideas for various recipients and occasions. It has 33.8k members who have made over 17k posts, making it a powerful source of data if it can be extracted and cleaned properly.
Data Exploration
Let’s take a look at a few of the post titles to get a better idea of what we are dealing with:
- Top 5 Last Minute Gift Ideas
- Trying to think of a not serious gift for my sister (27). She lives in Alaska if that makes a difference
- Get invited back next Xmas!
- South Asian -inspired Gift Ideas
- What same day delivery gift can I send my SO on his birthday, at work? This is a “secondary gift”
- need gift suggestions for friend(21,f)
- What is a good gift to get my girlfriend for our 3 year anniversary?
- Best buddy turns 30. No idea what to get him
- “I have 100 dollars to spend at target for a 19 year old girl, help?”.
Looking at the data, it is clear that we need to be careful with our extraction and standardizing. Many of the posts are gift guides (like 1, 3, and 4), and targets can show up in many different forms (girlfriend/her, friend/buddy, etc). We only care about authentic posts asking for gift ideas for a particular recipient. For these reasons simple keyword matching will not work well. Noted.
Data Extraction
The Reddit API only allows for the last 1000 posts to be scraped, but historic data is available via the pushshift.io API. We used this API to loop through the entire r/giftideas subreddit and pull out all 17,105 posts. As was seen with our data exploration, these posts are plain unstructured text and need to be standardized and cleaned in order to use them in our statistical analysis. Fortunately, recent advances in NLP have given us a great way of doing this.
Data Standardization
In order to make sense of all this unstructured data, we need to develop a way of transforming the post title into a simple label. Because the goal of this statistical analysis is to determine who people struggle to buy gifts for the most, we need a method of transforming text such as “I’m at a loss as to what to get my mother for christmas” into the simple label “mom”, since that is who they are struggling to buy for. As mentioned previously, keyword matching will not suffice, but fortunately for us this is a task that NLP is very well suited for.
Building the NLP Model
What is NLP?
NLP, or Natural Language Processing, is a subfield of artificial intelligence concerned with understanding human language. We won’t go into too much detail in this post, but this goes well beyond simple keyword searching, as NLP models can understand context and learn certain language tasks really well.
In this post we will be taking advantage of recent advances made in deep NLP which achieve better than human performance on a variety of tasks. Open sourced by Google in October 2018, Deep Bidirectional Transformers, or BERT, has revolutionized the field of NLP and has allowed computers to achieve never-before-seen accuracies at a number of different language challenges (https://arxiv.org/abs/1810.04805). BERT has been pre-trained on the entirety of Wikipedia, giving the model a great built-in understanding of the english language and context. We are about to unleash this beast on our gifting dataset.
Defining The Problem
The task best suited for the desired data transformation is title classification. Title classification attempts to classify an entire document (or in this case post) into a single class, or label. The idea is to train the model to classify posts into a single class, and then use that trained model to gather statistics on the rest of the data. Our labels will need to be predefined, and judging by a quick look at the posts, we can reasonably separate the data into 22 classes. These classes are:
- Friend
- Mom
- Dad
- Sister
- Brother
- Him – male significant other (boyfriend or husband)
- Her – female significant other (girlfriend or wife)
- Crush – unspecified significant other or crush
- Boy – male under 18
- Girl – female under 18
- Kid – under 18 but unspecified gender
- Gen man – any man that has not fallen into a different category
- Gen woman – any woman that has not fallen into a different category
- Grandpa
- Grandma
- Uncle
- Aunt
- Boss
- Coworker
- Couple
- Other – any person that does not fall into one of the other categories (ie. ‘Christmas gifts for spiritual people’)
- Irrelevant – any post that is not asking for a gift ideas (gift guides, self promoting gifts, spam, etc).
With these classes in mind, we can get started on training the model. Of course, you cannot train a model without having some annotated data to learn from, so I will have to go through a bunch of post titles and manually label them as belonging to one of the 22 classes. Not fun.
Annotating The Data
Oof. That was painful but after a few hours of manually labelling posts, I now have a dataset of 1900 annotated gift titles. For a pre-trained BERT model and a relatively simple task, this will be plenty. As with all machine learning tasks, it is important to randomly split the dataset into a training and a validation set in order to validate how the model is performing. Great – we now have a training set of 1600 posts and a validation set of 300 posts. Let’s get to the fun part and start training!
Model Training
I have just finished training the BERT model on the training dataset for 15 epochs, or full cycles, and the validation metrics have reached a point where I am confident in the models ability to label the rest of the gift titles. The metrics I am using to evaluate accuracy are F1, precision, and recall. More information on these metrics can be found here, but think of F1 score being very similar to the traditional accuracy while being able to handle uneven class distributions. Metrics for the training process throughout the 15 epochs can be seen in Figure 1 and 2 below.
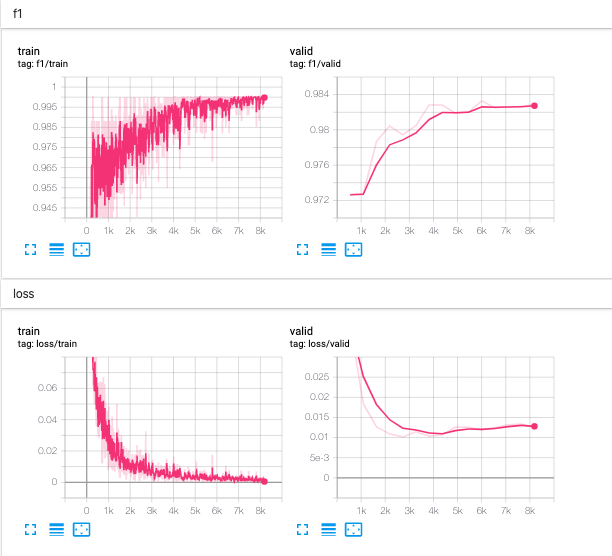
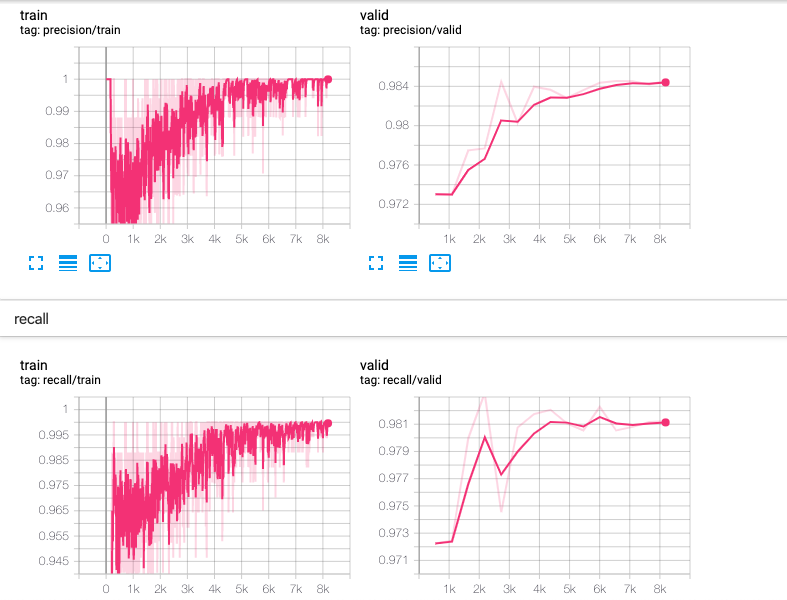
The model was able to achieve a training F1 score of 0.9981 which is an extremely good fit of the data. Moreover, the validation precision was 0.9846, validation recall was 0.9812, and validation F1 was 0.9821. This shows that the model is able to generalize really well to unseen posts, and that the model is ready to be unleashed on the remaining unlabelled data! But before we do that, let’s quickly visually validate the output of the model.
Visually Validating The Output
Here are some of the models predictions on various validation gift titles, to give you a better understanding of how the model is able to perform.
- Title: “Gift for 13 year old nephew, into video games/youtube, budget $130 Canadian (~$100 usd)”
Prediction: boy - Title: “Need ideas for my husband (40 m) – he has everything”
Prediction: him - Title: “Looking for a gift for my girlfriend (20)”
Prediction: her - Title: “Need ideas for GF whos birthday is also New Years Day”
Prediction: her - Title: “What should I buy for my boss’s wife?”
Prediction: wife - Title: “Personalized Shot Glasses”
Prediction: irrelevant - Title “Olive Wood Cheese Boards”
Prediction: irrelevant - Title: 12 Father’s Day Gifts From Etsy Your Dad Will Actually Want (PHOTOS)
Prediction: irrelevant - Title: Need a gift for a 21 year old french girl
Prediction: gen woman - Title: Gift for a 5-year-old boy whose grandfather buys him everything?
Prediction: boy
It is clear from the above examples that the model was able to learn the data extremely well at a near-human level. It was able to label gift guides and personal product ads as irrelevant, while also being able to correctly label the authentic gift questions. Great! We can now use this model to annotate the remaining unlabelled posts, and then aggregate the data and generate some interesting plots that can answer our burning statistical question!
What Does The Data Tell Us?
After using the model to relabel all 17105 gift titles, we were left with 12172 irrelevant titles and 4933 non-irrelevant titles. That’s a lot of gift guides, personal product advertisements and spam that can be removed! Let’s use these 4933 non-irrelevant titles to answer our burning question from the start which was: who do people struggle buying gifts for the most?
Visualization
The relevant gift targets were aggregated and plotted in different ways which can be seen in Figures 3 and 4 below.
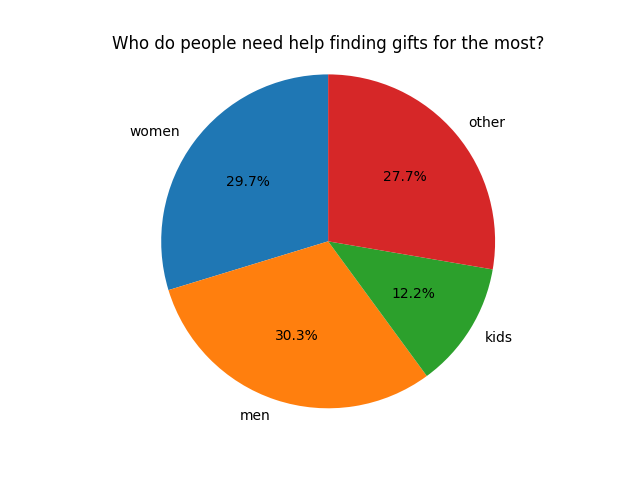
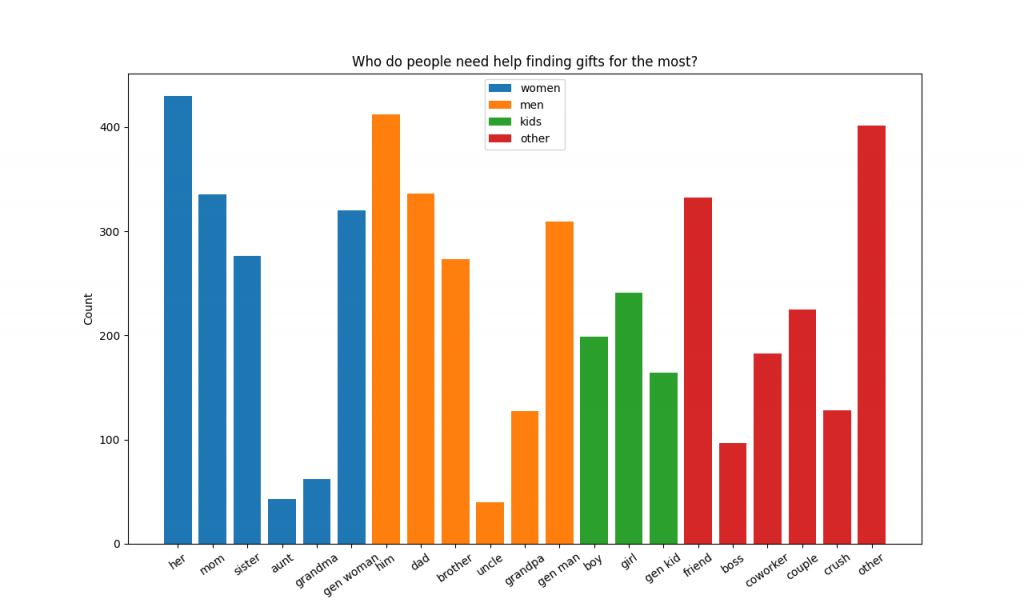
Who Do People Struggle Finding Gifts For
Figures 3 and 4 show us some very interesting information that can answer our burning question. It is clear that people need help with gift ideas for her and him the most. However, the ‘other’ class shows up almost just as much, showing us that peoples’ struggle with gift ideas are extremely long tail. This means that a lot of work needs to be done on our part to help people with gift ideas for all the long tail gift targets. Noted!
The next most frequent recipients for gift idea help are friend, mom, and dad. I was a little surprised to see friend so high up there – there must be a lot of really nice people out there giving gifts to their friends! We will definitely start helping people with gift ideas for friends in the coming weeks, don’t worry.
More evidence that people need help with long tail gift recipients comes from the fact that ‘gen man’ and ‘gen woman’ classes are so high on the list. This means a lot of people were asking questions like ‘best gifts for man who loves wine’, or ‘gift ideas for a man turning 30’. In future blog posts on gifting stats we will dig further into these classes to see the most common questions within the ‘gen man’, ‘gen woman’, and ‘other’ classes.
Other notable results are the fact that people need help finding gifts for coworkers and bosses a lot more than you’d think. We’ve made a post helping people with thoughtful gift ideas for their boss, but will need to start making more posts helping people with gift ideas for coworkers.
Caveats
A few caveats that must be addressed are:
- The model is not 100% accurate. This means that the papers that the model has labelled may not be correct 100% of the time. We do not believe this is such a problem however, since a validation F1 score of 0.9821 is near-human performance.
- Some posts contain more than one label. Sometimes a person may be asking for gift ideas for their dad and mom. The model cannot predict more than one class per post, meaning the model would either label these posts as one or the other. Fortunately, these posts are very few and should be negligible when the dataset becomes large enough.
- Reddit may not be a perfect representation of a population subset.
Future Work
This is only our first post exploring the cross between gifting and statistics, and there is still a lot that can be done! Future work items include:
- Incorporating the 63,169 posts from the subreddit r/gifts, giving us a much larger dataset to work with.
- Many of the posts contain a budget either as a flair or in the title itself, meaning we can begin to extract how much people are willing to spend on each recipient. This would be very interesting to know and will certainly be a topic of another blog post.
- Dig deeper into the long tail keywords to see some other large-ish categories of recipients that people need gift ideas for. Perhaps categories such as ‘gifts for mechanics’ or ‘gifts for star wars fans’ will present themselves!
- Explore the demographic of the people asking for gifting help (gender, age, etc).
Conclusion
In this post we used a data-driven approach to determine who people need help finding gifts for. If you managed to stick it out through the NLP and model training, congratulations! BERT is complicated and right on the cutting edge of current NLP research so if you are interested in deep NLP at all I recommend starting with that paper. Unleashing the power of BERT in order to gain an insight into the mind of the average gift buyer was quite fun, and I hope you learned something from this post along the way. If you have any questions or have any ideas for what my next post on gifting stats should be, feel free to reach out! I am always happy to know what people are interested in and am happy to use my knowledge of AI, machine learning, and statistics to help the world of gifters.